Breaking Down the I3D Network
Let's review a recent method for video classification. This week, I wanna discuss about I3D, yups, which is one of the best backbones for video classification. In fact, I wrote two papers, which were published on IEEE SPL and ICCV workshop, based on this network. Later, I will break down what is I3D, how we can use, and what are its limitations or future work?
Main Concept
This paper was published in CVPR 2017 and has been cited over 1,000 times. The main idea of this paper is to show how to gain advantages from a huge pretrained dataset, known as Kinetics. This dataset is composed by 400 clips per class with 51 classes inside. Another important idea was, the proposed method, called as Inflated 3D ConvNet (I3D) is based on 2D ConvNet inflation: filters and pooling kernels of very deep image classification are expanded into 3D. This work can learn seamless spatio-temporal features from video.
History (1): ConvNet+LSTM
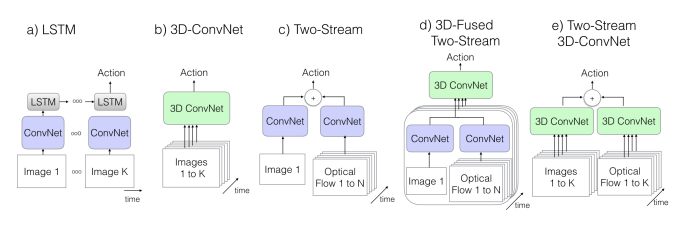
Back to the history, maybe we can review the first generation of action classification networks. What if we go with ConvNet+LSTM first? The use of this kind of networks are based on the spirit of bag-of-words image modelling methods that were popular a long time ago. However, this method suffers from temporal dependecies issue, such as the fact that the model cannot learn to distinguish opening from closing a door. Lately, the combination with LSTM, which can encode a state and capture a temporal ordering in long range dependencies, can be a solution to this issue. The implementation of this combination can be done by putting the LSTM layer with batch normalization after the last average pooling layer of Inception-V1, with 512 hidden units. Afterward, a FC layer can be added on the top to obtain the class probabilities.
History (2): 3D ConvNet
If we talk about 2D ConvNet, obviously we will face some issues regarding the training of a network with a set of parameters. On the other hand, the 3D ConvNet, which creates hierarchical representation of spatio-temporal data can reduce the parameters for training by reducing the additional kernel dimension of a 2D ConvNet.
History (3): Two-Stream Nets
Back again to LSTM, it can model the temporal ordering. However, it may not be able to capture fine low-level motions. Nevertheless, this information is essential. Now, thanks to Simonyan and Ziiserman, which provides a two-stream network to better capture the spatial and temporal information through the RGB and optical flow information. As for the implementation, these networks will be trained separately and and then fused in a later part of the procedure when testing on the video.
Now: I3D Network
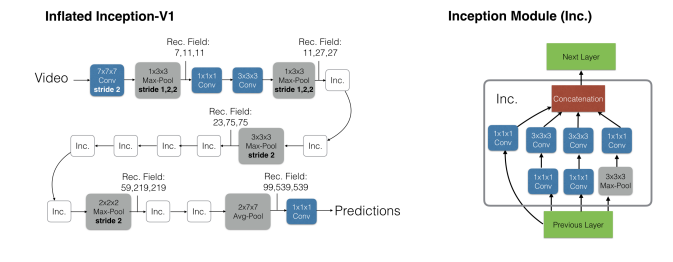
Inflating 2D ConvNets into 3D is the current approach used for video classification. It converts 2D classification models into 3D by training multiple frames at once instead of one by one. As for the implementation, it starts with a 2D net and inflates all the filters and pooling kernels. Hence, it can learn from multiple frames at once. The new filters are inflated so that they become
cubes instead of squares, for instance an originally N X N filter
would become N X N X N. Ohya, if the video is less than our predefined length, we can use a boring-video fixed point approach by simply repeating the video when it comes to the end.
The generation of the aforementioned networks are isllustrated in this figure below:
The I3D network is illustrated in this figure below:
I used I3D and extract features from Mixed_5c layers. In my papers, which are IEEE SPL and ICCV workshop, the I3D is used as the backbone and apply self-attention mechanism in the later part. In fact, some modifications is needed to further boost the performance.
Here, I provide my I3D model pretrained in Kinetics and finetuned in HMDB-51 dataset. You should obtain around 77% for the RGB and 80% for the combination of RGB and optical flow. Please kindly cite our paper if you use our model.
I3D model RGB Google Drive
I3D model Flow Google Drive
Cite our paper:
@article{purwanto2019three,
title={Three-stream Network with Bidirectional Self-attention for Action Recognition in Extreme Low Resolution Videos},
author={Purwanto, Didik and Pramono, Rizard Renanda Adhi and Chen, Yie-Tarng and Fang, Wen-Hsien},
journal={IEEE Signal Processing Letters},
year={2019},
publisher={IEEE}
}
@inproceedings{purwanto2019extreme,
title={Extreme Low Resolution Action Recognition with Spatial-Temporal Multi-Head Self-Attention and Knowledge Distillation},
author={Purwanto, Didik and Renanda Adhi Pramono, Rizard and Chen, Yie-Tarng and Fang, Wen-Hsien},
booktitle={Proceedings of the IEEE International Conference on Computer Vision Workshops},
pages={0--0},
year={2019}
}
Next Generation: Rethinking of the I3D
Now, we already know about I3D. But what's next?
In fact, there are some drawbacks of using I3D such as the computation time. In the paper, which entitled by "Rethinking Spatiotemporal Feature Learning:
Speed-Accuracy Trade-offs in Video Classification", some questions are arised:
– Do we even need 3D convolution? If so, what layers should we make 3D, and what
layers can be 2D? Does this depend on the nature of the dataset and task?
– Is it important that we convolve jointly over time and space, or would it suffice to
convolve over these dimensions independently?
– How can we use answers to the above questions to improve on prior methods in
terms of accuracy, speed and memory footprint?
Two different approaches, which are Bottom-Heavey-I3D and Top-Heavy-I3D, were performed with a network surgery. The purpose is to know whats the effective way to change the 3D convolution into 2D convolution to save the time. As the result, the Top-Heavy-I3D network achieves better performance and surprisingly can cut the training time.
The illustrations are provided here:
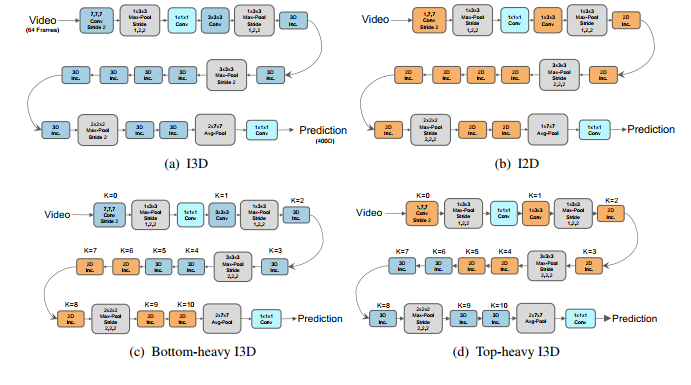
Replacing the 3D Convolution with 2D
As I mentioned earlier, changing the 3D into 2D may be the option to reduce the computation time. But, whats modification is effective? As discussed in here, the Top-Heavy architecture may obtain the optimal results in two huge dataset, Mini-Kinetics-200 and Something-something datasets. Under the same FLOPS, the Top-Heavy architecture consistenly obtain better performance than Bottom-Heavy network. This is because the Top-Heacy network can reduce the feature maps using spatial pooling before being convolved in 3D form. Also, this network can model temporal pattern amongst high level features that are essential to capture semantics mearning.
Practice (?)
As my experience, replacing the architecture inside the I3D may costly for researchers that have limited resources. Why? bacause train such a huge dataset is very challenging and time inefficient. For me, I prefer to use pretrained data and play in the latter part with some modification or combination. If we need faster outcome, let the beast company such Google or Facebook train the huge dataset for us.