Channel Separated Network
Paper Code
This week, I learned about channel separated convolution method and try to bring some idea from this paper to be applied in our work. First, I would like to discuss about the paper and give some comments afterward.
As we know that training video in huge dataset is relatively expensive, especially for 3D convolution network. Current 3D CNNs have complexity O(CTWH) as opposed to the cost of group convolution O(CWH), where T refers to the number of frames, H,W,C are the spatial dimension and number of channel, respectively.
On the other hand, group convolution has been shown to reduce the computational cost in various convolutional network for image classification. Hence, what if we apply into video classification? Also what factors matter the most in 3D group convolution architecture? and finally what are the best trade-offs between computation and the accuracy with 3D convolutinal architectures?
In this paper, it shows that the amount of channel interactions is a crucial to attain the optimal accuracy of 3D group convolutional networks. Two main things, first, it as a good practice to factorize 3D convolutions by separating channel interactions and spatiotemporal interactions. This can reduce the complexity while still keep a good accuracy. Second, 3D channel-separated convolutions provide a form of regularization, which can make the network achieve better accuracy in testing even attain lower accuracy during training. Hence, as conclusion, this paper propose Channel Separated Network (CSN), which is simple yet efficient by designing the network based on those findings.
This network is trained on Sports1M, Kinetics, and Something-Something datasets. These three datasets are considered as huge dataset.
In CSN, all operation are separated into either pointwise 1×1×1 or depthwise 3×3×3 convolutions. With this scheme, it can reduce FLOPs and parameters as long as high values of channel interaction are retained. It proposes two factorizations, which we call interaction-reduced and interaction-preserved. It is interesting to know that this scheme can
outperform or are comparable with the current state-of-the art methods on Sports1M, Kinetics, and Something-Something while being 2–3 times faster.
For better understanding, I would like to discuss about channel separation in more detail here. Fig. 1 shows the differences among 3D convolution networks.
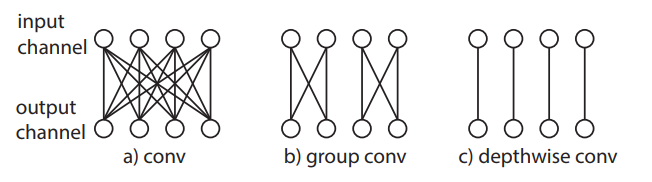
As shown there, convolutional filters can be partitioned into groups with each filter receiving input from channels only within its group. (a) A conventional convolution, which has only one group. (b) A group convolution with 2 groups. (c) A depthwise convolution where the number of groups matches the number of input/output filters, i.e., each group contains only one channel. Figs. 2, 3, and 4 show about the ResNet development for channel separation convolution.
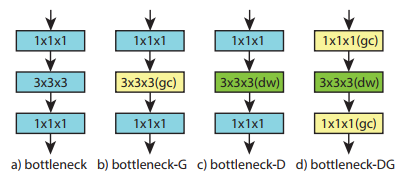

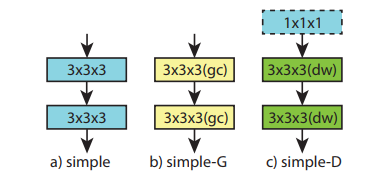
For my comments, I think we can try to use or modify CSN rather than use I3D. This is because CSN can achieve acceptable result while reduce the training time 2-3 times. Also, CSN seems more compact compared to I3D. The third concern, the current state-of-the-art methods are use depth-wise approaches instead traditional 3D convolution.