Gate-Shift Network
Paper
This week, I learned about channel decomposition in 3D CNN called as Gate-Shift Module (GSM) \cite{sudhakaran2019gate}. This network is one of the latest update on how to decompose the deep 3D CNN networks. It is challenging, because deep 3D CNN networks have large number of parameters. Hence, the computation will be expensive. Furthermore, this deep network also should be trained on huge dataset as well.
Deep C3D netowrks are designed to learn robust representations in the joint spatio-temporal feature space with additional parameters in 3D kernels fashion and more computation. Current methods, which try to decompose the 3D CNN, is based on factorization 3D spatio-temporal kernels into 2D spatial plus 1D temporal, such as P3D, R(2+1)D, and S3D. The other method is CSN, which based on channel space via group convolution.
The other work, GST, is based on modelling both spatial and spatio-temporal interaction in parallel with 2D and 3D convolution on separated channel groups. More recent work, TSM, is based on a constrained temporal convolution to hard-coded time-shifts that move some of channels forward in time or backward.
The GSM is lightweight model, which turns the 2D CNN into a highly efficient spatio-temporal feature desciptor.
The GSM first
applies 2D convolution, then decomposes the output tensor using a learnable spatial gating into two tensors: a
gated version of it, and its residual. The gated tensor goes
through a 1D temporal convolution while its residual is
skip-connected to its output. We implement spatial gating as group spatio-temporal convolution with single output plane per group. We use hard-coded time-shift of channel groups instead of learnable temporal convolution. With
GSM plugged in, a 2D-CNN learns to adaptively route features through time and combine them, at almost no additional parameters and computational overhead.
The TSN network itself is a temporal pooling based method which works on frame-level features.

As shown in Figure above, there are many kinds of 3D kernel factorization for spatio-temporal learning in video. Existing methods decompose into channelwise (CSN), which I have reviewed last week, spatial followed by temporal (S3D, TSM), or grouped spatial and spatio-temporal (GST). For all of them,
spatial, temporal, and channel-wise interaction is hardwired.
here, the GSM learns group
spatial gating (blocks in green) to control interactions in
spatial-temporal decomposition. GSM is lightweight and a
building block of high performing video feature extractors.
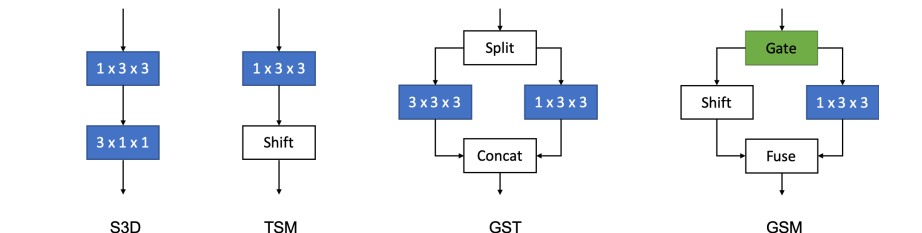
As shown in Figure above, C3D decomposition approaches in comparison to GSM schematics. GSM is inspired by GST and TSM but replaces the hard-wired channel split with a learnable spatial gating block. Thereafter, the GSM implementation with group gating and
forward-backward temporal shift. A gate is a single 3D
convolution kernel with tanh calibration, thus very few parameters are added when GSM is used to turn a C2D base
model into a spatio-temporal feature extractor. It is as shown in Figure below.
